

Git es utilizado hoy en día por una gran cantidad de desarrolladores -por ejemplo el núcleo Linux, de hecho Linus Torvalds fue el creador de git- como sistema de control de versiones de código. Sin embargo, también puede ser muy útil para administradores de sistemas y devops para crear repositorios que almacenen scripts, documentación, automatizaciones, etc… de los que luego se pueda hacer uso personal o colaborativo en una organización o proyecto.
Sin ir más lejos, en mi caso tengo algunos de mis scripts en repositorios públicos de mi cuenta de GitHub, diseñado especialmente para proyectos colaborativos. Para proyectos más personales tengo BitBucket que permite repositorios privados gratis.
En el quehacer del día a día he ido realizando un tutorial que pueda resultar útil a otros sysadmins de una forma “descafeinada”. No entraremos pues en materia demasiado extensa que suele afectar únicamente a desarrollo, pretendo crear una guía práctica con la que ponerse en marcha en poco tiempo en el uso de git.
Algunas convenciones para el artículo:
- Usuario para git en el servidor git –> jota
- Hostname del servidor git –> gitserver
Veremos:
- Instalación de git en el servidor.
- Creación de repositorios en el servidor.
- Empezar a trabajar en nuestro entorno de escritorio local con los repos anteriormente creados.
- Soluciones a problemas comunes en el uso de git.
Primer paso: instalar Git en el servidor
Utilizaremos la herramienta de paquetería correspondiente según nuestra distro:
# Red Hat & derivadas yum install git # Debian & derivadas apt install git # Arch Linux pacman -Syu git
Crear nuestro primer repositorio en el servidor
En nuestro servidor almacenaremos todos los repositorios en los que vayamos a trabajar. Crearemos un directorio central en el que iremos creando los distintos repos:
mkdir /opt/mis-repositorios cd /opt/mis-repositorios
Una vez en este directorio, crearemos tantos repos como necesitemos:
mkdir repositorio-1.git mkdir repositorio-2.git mkdir repositorio-3.git ...
Tendremos por otro lado que inicializarlos. Aquí pueden entrar las primeras dudas, ya que mirando documentación de diversas fuentes podemos observar que en ocasiones se inicializa un repositorio con git init o bien con git init --bare. Para simplificar las cosas:
git inites utilizado para inicializar un repositorio en nuestro espacio de trabajo local. No acepta commits de otros colaboradores.git init --baresin embargo se utiliza para inicializar un repositorio central sobre el que se van a realizar commits, ya sean sólo nuestros o de más colaboradores. Cuando creamos un repositorio en el servidor, estamos por tanto buscando esto último.
Así pues, inicializaremos los repositorios que hemos creado anteriormente:
cd /opt/mis-repositorios/repositorio-1.git git init --bare cd /opt/mis-repositorios/repositorio-2.git git init --bare ...
Opciones de configuración adicionales con git config
Una vez inicializados nuestros repos, podemos personalizar nuestra configuración con git config. Estas opciones pueden configurarse a nivel local de cada repositorio o bien a nivel global para todos los repositorios del servidor.
A nivel local, nos situamos en el repositorio donde queremos configurar:
cd /opt/mis-repositorios/repositorio-1
Y configuramos el usuario y el correo:
git config user.name "jota" git config user.email jota@example.com
Si quisiéramos hacerlo a nivel global añadiremos la opción --global
git config --global user.name "jota" git config --global user.email jota@example.com
Para revisar las opciones de configuración que hay aplicadas, nos situamos en el repo correspondiente y hacemos un git config --list:
cd /opt/mis-repositorios/repositorio-1 git config --list
Git en el cliente: trabajando con nuestro repositorio en local
Llegados a este punto, la idea es trabajar desde nuestro escritorio con nuestro editor de código o IDE favorito. Tendremos que instalar primero git, siguiendo el mismo procedimiento que al principio del artículo con la herramienta de paquetería adecuada. Si vamos a trabajar desde Windows tenemos también el instalador correspondiente.
Una vez instalado, para empezar a trabajar en local hay dos aproximaciones:
- Creamos un repo en local y lo vinculamos al repositorio remoto. Opción útil si ya teníamos un directorio con todos los ficheros y código que queremos subir al repo remoto que hemos creado en el servidor. Como estamos empezando a trabajar con git, no estamos buscando esto pero os comento cómo proceder:
# En nuestro local, creamos el directorio del repo mkdir /opt/mis-repositorios/repositorio-1 cd /opt/mis-repositorios/repositorio-1 # Inicializamos el repositorio local git init # Indicamos la URL del repositorio remoto del servidor git remote add origin ssh://jota@gitserver/opt/mis-repositorios/repositorio-1.git # Añadimos los ficheros git add * # Hacemos commit git commit "Commit inicial" # Subimos al repo el contenido git push origin master
- Simplemente clonamos el repositorio remoto. Ya que hemos creado un repositorio desde cero en nuestro servidor, esta opción es la que estamos buscando y además es la más sencilla y recomendable:
# Nos situamos en el directorio donde vamos a clonar nuestro repo cd /home/jota/repositorios # Clonamos git clone ssh://jota@gitserver/opt/mis-repositorios/repositorio-1.git
Cómo seguir trabajando en nuestro repo a nivel local
Ahora ya tenemos todo listo para trabajar. Dentro de /home/jota/repositorios/repositorio-1.git iremos añadiendo ficheros, cambiando código, etc… Pongamos por caso que creo el script mi-script.py en el repositorio. ¿Cómo lo subo al repositorio del servidor? Muy fácil:
# Añade el fichero que quieres subir al repo. Si son varios puedes hacer git add * git add mi-script.py # Realiza el commit git commit -m "Subida del script mi-script.py" # Realiza push para subir finalmente el contenido al repo remoto git push origin master
Cómo sincronizar nuestro repositorio local con las últimas novedades del remoto
Si varias personas han estado trabajando en el repositorio, cuando nosotros vayamos a hacer algo en local estaremos desactualizados. Para sincronizarlo con las últimas novedades del remoto haremos:
git pull origin master
Como hemos visto, la diferencia entre pull y push es básica para comprender el flujo de trabajo con respositorios remotos:
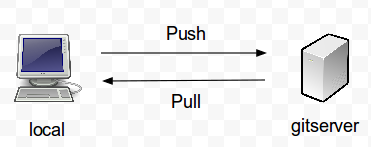
Mover y eliminar ficheros
Si queremos eliminar un fichero del repositorio utilizaremos git rm:
git rm mi-script.py git commit -m "Fichero mi-script.py eliminado del repositorio" git push origin master
Para mover ficheros, utilizaremos git mv:
git mv mi-script.py mi-script2.py git commit -m "Fichero mi-script.py renombrado a mi-script2.py" git push origin master
¡Me equivoqué al realizar git add!
No hay problema:
# Haz reset del add que pasaste a un fichero git reset <fichero> # Reset de todos los ficheros que añadiste con git add git reset
Si por el contrario hemos realizado un git add y se nos olvidó añadir por ejemplo otro fichero, podemos hacer:
git add fichero-2 git commit --amend
¡Maldición, no tendría que haber hecho ese commit!
Tampoco es el fin del mundo:
# Realizamos reset del commit, respetando los cambios que ya hemos realizado en los ficheros git reset HEAD~ # Modificamos los ficheros que habíamos olvidado tocar anteriormente # Añadimos esos ficheros para el nuevo commit git add fichero-2 fichero-3 ... # Realizamos commit git commit -c ORIG_HEAD
Todavía más
Git da mucho juego. Como comentaba al principio, esta se trata de una guía práctica para los usos más comunes que podamos hacer de git. No hemos tratado por ejemplo el tema de las ramas (branches) ya que entran más en juego en el ámbito de Desarrollo. No obstante, queda más git para artículos posteriores 🙂